Troubleshooting
Here are some common errors and their resolutions. This is not comprehensive. The issue tracker has a wealth of information and user-contributed examples.
Many of these errors have been fixed in newer releases! Ensure that the latest version of the library is being used. Some legacy endpoints are out of date. Review the Installation instructions.
If issues are not covered in the docs or the issue tracker, or if a solution is not discussed in the documentation, we would appreciate a bug report.
Special thanks to the early adopters and users for discovering and sharing many workarounds and solutions!
Errors
Uncaught TypeError: Cannot read property of undefined
Errors include
Uncaught TypeError: Cannot read property 'read' of undefined
Uncaught TypeError: Cannot read property 'writeFile' of undefined
Uncaught TypeError: Cannot read property 'utils' of undefined
The root cause is an undefined XLSX variable. This usually means the library
was not properly loaded.
Review the Installation instructions.
If the error shows up while using the latest version, projects may require other configuration or loading strategies.
Upgrade Note (click to show)
Older versions of the library only shipped with CommonJS and standalone script. Webpack and other bundlers supported CommonJS dependencies with default import:
// old way
import XLSX from "xlsx";
Newer versions of the library ship with an ESM build. When upgrading, imports should be updated:
// new way
import * as XLSX from "xlsx";
import * as cptable from "xlsx/dist/cpexcel.full.mjs";
XLSX.set_cptable(cptable);
Newer releases support tree shaking, and special methods like writeFileXLSX
help reduce bundle size.
The bundler note explains in further detail.
"Aw Snap!" or "Oops, an error has occurred!"
Browsers have strict memory limits and large spreadsheets can exceed the limits.
For large worksheets, use dense worksheets:
var wb = XLSX.read(data, {dense: true}); // creates a dense-mode sheet
XLSX.writeFile(data, "large.xlsx"); // writeFile can handle dense-mode sheets
When processing very large files is a must, consider running processes in the server with NodeJS or some other server-side technology.
If the files are small, please report to our issue tracker
Sparse worksheets historically were more performant in small sheets. Due to a 2014 bug in V8 and a 2017 regression in V8 (the JavaScript engine powering Node and Chrome), large sparse worksheets will crash the web browser.
"Invalid String Length" or ERR_STRING_TOO_LONG
V8 (Node/Chrome) have a maximum string length that has changed over the years.
Node 16 and Chrome 106 enforce a limit of 0x1fffffe8 (536870888) characters.
A 2017 V8 discussion
explains some of the background behind the V8 decision.
XLSX and ODS are ZIP-based formats that store worksheets in XML entries. In worksheets with over 100M cells, the XML strings may exceed the V8 limit!
Depending on the environment, this issue may result in missing worksheets; error
messages such as Invalid string length, ERR_STRING_TOO_LONG, or
Cannot create a string longer than 0x1fffffe8 characters; or browser crashes.
A number of bugs have been reported to the V8 and Chromium projects on this subject, some of which have been open for nearly a decade.
Please leave a note including worksheet sizes (number of rows/columns and file size) and environment (browser or NodeJS or other platform).
The "Excel Binary Workbook" XLSB format uses a binary representation. The XLSB parser is not affected by this issue.
XLSB files are typically smaller than equivalent XLSX files. There are other Excel performance benefits to XLSB, so it is strongly recommended to use XLSB when possible.
Invalid HTML: could not find table
Data can be fetched and parsed by the library:
const response = await fetch("test.xlsx");
const wb = XLSX.read(await response.arrayBuffer());
If the file does not exist, servers will send a 404 response that may include a friendly HTML page. Without checking the response code, the integration will try to read the 404 page and fail since the HTML typically has no TABLE elements.
Integration code should defend against network issues by checking status code.
For example, when using fetch:
async function fetch_workbook_and_error_on_404(url) {
const response = await fetch(url);
if(res.status == 404) throw new Error("404 File Not Found");
const ab = await response.arrayBuffer();
return XLSX.read(ab);
}
When building a project with create-react-app or other templates, spreadsheets
must be placed in the public folder. That folder is typically served by the
dev server and copied to the production site in the build process.
Cloudflare Worker "Error: Script startup exceeded CPU time limit."
This may show up in projects with many dependencies. The official workaround is
dynamic import. For example:
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const XLSX = await import("xlsx"); // dynamic import
const wb = XLSX.read("abc\n123", {type: "string"});
const buf = XLSX.write(wb, {type: "buffer", bookType: "xlsb"});
const response = new Response(buf);
response.headers.set("Content-Disposition", 'attachment; filename="cf.xlsb"');
return response;
},
};
"require is not defined"
This error will be displayed in the browser console and will point to xlsx.mjs
Older versions of Webpack do not support mjs for ECMAScript Modules. This
typically affects older create-react-app projects.
The "Standalone" build should
be loaded using require or import:
CommonJS
var XLSX = require("xlsx/dist/xlsx.full.min");
ECMAScript Modules
import * as XLSX from "xlsx/dist/xlsx.full.min.js";
SCRIPT5022: DataCloneError
IE10 does not properly support Transferable.
Object doesn't support property or method 'slice'
IE does not implement Uint8Array#slice. An implementation is included in the
shim script. Check the "Standalone" Installation note
TypeError: f.substr is not a function
Some Google systems use the base64url encoding. base64url and base64 are
different encodings. A simple regular expression can translate the data:
var wb = XLSX.read(b64.replace(/_/g, "/").replace(/-/g, "+"), {type:'base64'});
Error: Cannot read property '0' of undefined
FileReader#readAsText will corrupt binary data including XLSX, XLSB, XLS, and
other binary spreadsheet files.
Applications should use FileReader#readAsArrayBuffer or Blob#arrayBuffer.
Examples are included in "User Submissions"
Applications specifically targeting legacy browsers like IE10 should use
FileReader#readAsBinaryString to read the data and call XLSX.read using the
binary type.
Unsupported file undefined when reading ArrayBuffer objects
Old versions of the library did not automatically detect ArrayBuffer objects.
Workaround (click to show)
This solution is not recommended for production deployments. Native support
for ArrayBuffer was added in library version 0.9.9.
After reading data with FileReader#readAsArrayBuffer, manually translate to
binary string and call XLSX.read with type "binary"
document.getElementById('file-object').addEventListener("change", function(e) {
var files = e.target.files,file;
if (!files || files.length == 0) return;
file = files[0];
var fileReader = new FileReader();
fileReader.onload = function (e) {
var filename = file.name;
// pre-process data
var binary = "";
var bytes = new Uint8Array(e.target.result);
var length = bytes.byteLength;
for (var i = 0; i < length; i++) {
binary += String.fromCharCode(bytes[i]);
}
// call 'xlsx' to read the file
var oFile = XLSX.read(binary, {type: 'binary', cellDates:true, cellStyles:true});
};
fileReader.readAsArrayBuffer(file);
});
Browser is stuck!
By default, operations run in the main renderer context and block the browser from updating. Web Workers offload the hard work to separate contexts, freeing up the renderer to update.
Strange exported file names in the web browser
JS and the DOM API do not have a standard approach for creating files. There was
a saveAs proposal as part of "File API: Writer" but it was abandoned in 2014.
The library integrates a number of platform-specific techniques for different
environments. In modern web browsers, the library creates an A element with
the download attribute and clicks the link. A full analysis is included in the
"Local File Access" demo
If the filename looks like a UUID (hexadecimal characters and hyphens), this is a known issue with Google Tag Manager (GTM) rewriting links. There is a special workaround for sites that use GTM.
Third party libraries like FileSaver.js provide an implementation of saveAs
that include more browser-specific workarounds.
FileSaver.js integration (click to show)
Standalone Build
<script src="https://unpkg.com/[email protected]/dist/FileSaver.js"></script>
<script src="https://cdn.sheetjs.com/xlsx-0.20.3/package/dist/xlsx.full.min.js"></script>
<!-- XLSX.writeFile will use the FileSaver `saveAs` implementation -->
Frameworks and Bundlers
At the time of writing, [email protected] leaks saveAs to the global scope,
so merely importing the module works:
import FileSaver from 'file-saver'; // as a side effect, `saveAs` is visible
import { writeFile } from 'xlsx'; // writeFile will use the global `saveAs`
"Cannot save file" in NodeJS
The fs module is automatically loaded in scripts using require:
var XLSX = require("xlsx"); // automatically loads `fs`
Using the ESM import,
the fs module must be imported and passed to the library:
import * as XLSX from 'xlsx';
/* load 'fs' for readFile and writeFile support */
import * as fs from 'fs';
XLSX.set_fs(fs);
Data Issues
Generated XLSX files are very large!
By default, compression is disabled. Set the option compression: true in the
write or writeFile options object. For example:
XLSX.writeFile(workbook, "export.xlsx", { compression: true });
CSV and XLS files with Chinese or Japanese characters look garbled
The ESM build, used in tools like Webpack and in Deno, does not include the codepage tables by default. The "Frameworks and Bundlers" section explains how to load support.
DBF files with Chinese or Japanese characters have underscores
As mentioned in the previous answer, codepage tables must be loaded.
When reading legacy files that do not include character set metadata, the
codepage option controls the codepage. Common values:
codepage | Description |
|---|---|
| 874 | Windows Thai |
| 932 | Japanese Shift-JIS |
| 936 | Simplified Chinese GBK |
| 950 | Traditional Chinese Big5 |
| 1200 | UTF-16 Little Endian |
| 1252 | Windows Latin 1 |
When writing files in legacy formats like DBF, the default codepage 1252 will be used. The codepage option will override the setting. Any characters missing from the character set will be replaced with underscores.
Worksheet only includes one row of data
Some third-party writer tools will not update the dimensions records in XLSX or XLS or XLSB exports. SheetJS utility functions will skip values not in range.
The following helper function will recalculate the range:
function update_sheet_range(ws) {
var range = {s:{r:Infinity, c:Infinity},e:{r:0,c:0}};
Object.keys(ws).filter(function(x) { return x.charAt(0) != "!"; }).map(XLSX.utils.decode_cell).forEach(function(x) {
range.s.c = Math.min(range.s.c, x.c); range.s.r = Math.min(range.s.r, x.r);
range.e.c = Math.max(range.e.c, x.c); range.e.r = Math.max(range.e.r, x.r);
});
ws['!ref'] = XLSX.utils.encode_range(range);
}
More Code Snippets (click to show)
set_sheet_range changes a sheet's range given a general target spec that can include only the start or end cell:
/* given the old range and a new range spec, produce the new range */
function change_range(old, range) {
var oldrng = XLSX.utils.decode_range(old), newrng;
if(typeof range == "string") {
if(range.charAt(0) == ":") newrng = {e:XLSX.utils.decode_cell(range.substr(1))};
else if(range.charAt(range.length - 1) == ":") newrng = {s:XLSX.utils.decode_cell(range.substr(0, range.length - 1))};
else newrng = XLSX.utils.decode_range(range);
} else newrng = range;
if(newrng.s) {
if(newrng.s.c != null) oldrng.s.c = newrng.s.c;
if(newrng.s.r != null) oldrng.s.r = newrng.s.r;
}
if(newrng.e) {
if(newrng.e.c != null) oldrng.e.c = newrng.e.c;
if(newrng.e.r != null) oldrng.e.r = newrng.e.r;
}
return XLSX.utils.encode_range(oldrng);
}
/* call change_sheet and modify worksheet */
function set_sheet_range(sheet, range) {
sheet['!ref'] = change_range(sheet['!ref'], range);
}
Adding a cell to a range
function range_add_cell(range, cell) {
var rng = XLSX.utils.decode_range(range);
var c = typeof cell == 'string' ? XLSX.utils.decode_cell(cell) : cell;
if(rng.s.r > c.r) rng.s.r = c.r;
if(rng.s.c > c.c) rng.s.c = c.c;
if(rng.e.r < c.r) rng.e.r = c.r;
if(rng.e.c < c.c) rng.e.c = c.c;
return XLSX.utils.encode_range(rng);
}
range_add_cell("A1:C3","B2")
function add_to_sheet(sheet, cell) {
sheet['!ref'] = range_add_cell(sheet['!ref'], cell);
}
Some decimal values are rounded
Excel appears to round values in certain cases. It is suspected that the XLSX
parser handles 15 decimal digits of precision. This results in inaccuracies such
as 7581185.559999999 rounding to 7581185.56 and 7581185.5599999903
rounding to 7581185.55999999.
See Issue 3003 in the main SheetJS CE repo for details.
Corrupt files
Third-party build tools and frameworks may post-process SheetJS scripts. The changes may result in corrupt files.
In the web browser, the standalone scripts from the SheetJS CDN will use proper
encodings and should work in applications. The scripts typically can be added
to an index.html file, bypassing any third-party post-processing
There are known bugs with the SWC minifier (used in Next.js 13+). The original
minifier can be enabled by setting swcMinify: false in next.config.js.
This file should be served over HTTPS
writeFile uses platform APIs to download files. In browsers, writeFile uses
the download attribute.
Newer versions of Google Chrome and other browsers will block these downloads from "insecure contexts" (when served over HTTP rather than HTTPS). Users may be presented with the option to "keep" or "save" the file:
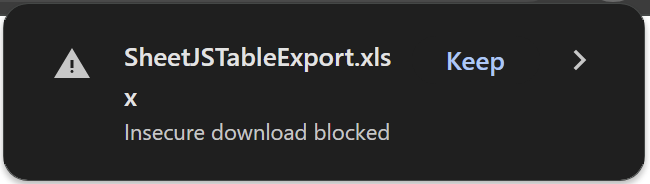
These limitations are enforced by the browser. It is strongly recommended to serve websites over HTTPS when possible.
See issue #3145 for a longer discussion.