Loader Tutorial
Many existing systems and platforms include support for loading data from CSV files. Many users prefer to work in spreadsheet software and multi-sheet file formats including XLSX. SheetJS libraries help bridge the gap by translating complex workbooks to simple CSV data.
The goal of this example is to load spreadsheet data into a vector store and use a large language model to generate queries based on English language input. The existing tooling supports CSV but does not support real spreadsheets.
In "SheetJS Conversion", we will use SheetJS libraries to generate CSV files for the LangChainJS CSV loader. These conversions can be run in a preprocessing step without disrupting existing CSV workflows.
In "SheetJS Loader", we will use SheetJS libraries in a
custom LoadOfSheet data loader to directly generate documents and metadata.
"SheetJS Loader Demo" is a complete demo that uses the SheetJS Loader to answer questions based on data from a XLS workbook.
This demo was tested in the following configurations:
| Platform | Architecture | Date |
|---|---|---|
| NVIDIA RTX 5090 (32 GB VRAM) + Ryzen Z1 Extreme (24 GB RAM) | win11-x64 | 2025-06-17 |
| NVIDIA RTX 5090 (32 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | linux-x64 | 2025-06-20 |
| NVIDIA RTX 4090 (24 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | win11-x64 | 2025-04-17 |
| NVIDIA RTX 4090 (24 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | linux-x64 | 2025-06-20 |
| AMD RX 7900 XTX (24 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | win11-x64 | 2025-06-20 |
| AMD RX 7900 XTX (24 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | linux-x64 | 2025-06-21 |
| Intel Arc B580 (12 GB VRAM) + Ryzen Z1 Extreme (24 GB RAM) | win11-x64 | 2025-06-20 |
| Intel Arc B580 (12 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | linux-x64 | 2025-06-21 |
| Apple M4 Max 16-Core CPU + 40-Core GPU (48 GB unified memory) | darwin-arm | 2025-03-06 |
| Apple M3 Ultra 28-Core CPU + 60-Core GPU (96 GB unified memory) | darwin-arm | 2025-06-24 |
| Apple M2 Max 12-Core CPU + 30-Core GPU (32 GB unified memory) | darwin-arm | 2025-03-25 |
SheetJS users have verified this demo in other configurations:
Other tested configurations (click to show)
| Platform | Architecture | Demo |
|---|---|---|
| NVIDIA L40 (48 GB VRAM) + i9-13900K (32 GB RAM) | linux-x64 | LangChainJS |
| NVIDIA RTX 4080 SUPER (16 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | win11-x64 | LangChainJS |
| NVIDIA RTX 4070 Ti SUPER (16 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | win11-x64 | LangChainJS |
| NVIDIA RTX 4070 Ti (12 GB VRAM) + Ryzen 7 5800x (64 GB RAM) | win11-x64 | LangChainJS |
| NVIDIA RTX 4060 (8 GB VRAM) + Ryzen 7 5700g (32 GB RAM) | win11-x64 | LangChainJS |
| NVIDIA RTX 3090 (24 GB VRAM) + Ryzen 9 3900XT (128 GB RAM) | win11-x64 | LangChainJS |
| NVIDIA RTX 3080 (12 GB VRAM) + Ryzen 7 5800X (32 GB RAM) | win11-x64 | LangChainJS |
| NVIDIA RTX 3070 (8 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | win11-x64 | LangChainJS |
| NVIDIA RTX 3060 (12 GB VRAM) + i5-11400 (32 GB RAM) | win10-x64 | LangChainJS |
| NVIDIA RTX 2080 (12 GB VRAM) + i7-9700K (16 GB RAM) | win10-x64 | LangChainJS |
| NVIDIA RTX 2070 (8 GB VRAM) + Ryzen 7 3700x (80 GB RAM) | linux-x64 | LangChainJS |
| NVIDIA RTX 2060 (6 GB VRAM) + Ryzen 5 3600 (32 GB RAM) | win10-x64 | LangChainJS |
| NVIDIA GTX 1080 (8 GB VRAM) + Ryzen 7 5800x (64 GB RAM) | win10-x64 | LangChainJS |
| NVIDIA GTX 1070 (8 GB VRAM) + Ryzen 7 7700x (32 GB RAM) | win11-x64 | LangChainJS |
| AMD RX 6800 XT (16 GB VRAM) + Ryzen Z1 Extreme (16 GB RAM) | win11-x64 | LangChainJS |
| Apple M4 10-Core CPU + 10-Core GPU (24 GB unified memory) | darwin-arm | LangChainJS |
Special thanks to the following users for testing with multiple configurations:
CSV Loader
This explanation was verified against LangChainJS 0.2.
Document loaders generate data objects ("documents") and associated metadata from data sources.
LangChainJS offers a CSVLoader1 component for loading CSV data from a file:
import { CSVLoader } from "@langchain/community/document_loaders/fs/csv";
const loader = new CSVLoader("pres.csv");
const docs = await loader.load();
console.log(docs);
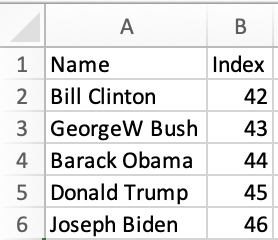
The CSV loader uses the first row to determine column headers and generates one document per data row. For example, the following CSV holds Presidential data:
Name,Index
Bill Clinton,42
GeorgeW Bush,43
Barack Obama,44
Donald Trump,45
Joseph Biden,46
Each data row is translated to a document whose content is a list of attributes and values. For example, the third data row is shown below:
| CSV Row | Document Content |
|---|---|
| |
The LangChainJS CSV loader will include source metadata in the document:
Document {
pageContent: 'Name: Barack Obama\nIndex: 44',
metadata: { source: 'pres.csv', line: 3 }
}
SheetJS Conversion
The SheetJS NodeJS module can be imported in NodeJS scripts that use LangChainJS and other JavaScript libraries.
A simple pre-processing step can convert workbooks to CSV files that can be processed by the existing CSV tooling:
Parsing files from the filesystem
The SheetJS readFile method2 can read workbook files. The method accepts a
path and returns a workbook object that conforms to the SheetJS data model3.
/* Load SheetJS Libraries */
import { readFile, set_fs } from 'xlsx';
/* Load 'fs' for readFile support */
import * as fs from 'fs';
set_fs(fs);
/* Parse `pres.xlsx` */
const wb = readFile("pres.xlsx");
Inspecting SheetJS workbook and worksheet objects
Workbook objects represent multi-sheet workbook files. They store individual worksheet objects and other metadata.
Relevant to this discussion, the workbook object uses the following keys4:
SheetNamesis an array of worksheet namesSheetsis an object whose keys are sheet names and whose values are sheet objects.
SheetNames[0] is the first worksheet name, so the following snippet will pull
the first worksheet from the workbook:
const first_ws = wb.Sheets[wb.SheetNames[0]];
Exporting SheetJS worksheets to CSV
Each worksheet in the workbook can be written to CSV text using the SheetJS
sheet_to_csv5 method. The method accepts a SheetJS worksheet object and
returns a string.
const csv = utils.sheet_to_csv(first_ws);
Complete Script
For example, the following NodeJS script reads pres.xlsx and displays CSV rows
from the first worksheet:
/* Load SheetJS Libraries */
import { readFile, set_fs, utils } from 'xlsx';
/* Load 'fs' for readFile support */
import * as fs from 'fs';
set_fs(fs);
/* Parse `pres.xlsx` */
const wb = readFile("pres.xlsx");
/* Print CSV rows from first worksheet */
const first_ws = wb.Sheets[wb.SheetNames[0]];
const csv = utils.sheet_to_csv(first_ws);
console.log(csv);
Similar Workflows
A number of demos cover spiritually similar workflows:
-
Stata, MATLAB and Maple support XLSX data import. The SheetJS integrations generate clean XLSX workbooks from user-supplied spreadsheets.
-
TensorFlow.js, Pandas and Mathematica support CSV data import. The SheetJS integrations generate clean CSVs and use built-in CSV processors.
-
The "Command-Line Tools" demo covers techniques for making standalone command-line tools for file conversion.
Single Worksheet
For a single worksheet, a SheetJS pre-processing step can write the CSV rows to
file and the CSVLoader can load the newly written file.
Code example (click to hide)
import { CSVLoader } from "@langchain/community/document_loaders/fs/csv";
import { readFile, set_fs, utils } from 'xlsx';
/* Load 'fs' for readFile support */
import * as fs from 'fs';
set_fs(fs);
/* Parse `pres.xlsx`` */
const wb = readFile("pres.xlsx");
/* Generate CSV and write to `pres.xlsx.csv` */
const first_ws = wb.Sheets[wb.SheetNames[0]];
const csv = utils.sheet_to_csv(first_ws);
fs.writeFileSync("pres.xlsx.csv", csv);
/* Create documents with CSVLoader */
const loader = new CSVLoader("pres.xlsx.csv");
const docs = await loader.load();
console.log(docs);
// ...
Workbook
A workbook is a collection of worksheets. Each worksheet can be exported to a
separate CSV. If the CSVs are written to a subfolder, a DirectoryLoader6
can process the files in one step.
Code example (click to hide)
In this example, the script creates a subfolder named csv. Each worksheet in
the workbook will be processed and the generated CSV will be stored to numbered
files. The first worksheet will be stored to csv/0.csv.
import { CSVLoader } from "@langchain/community/document_loaders/fs/csv";
import { DirectoryLoader } from "langchain/document_loaders/fs/directory";
import { readFile, set_fs, utils } from 'xlsx';
/* Load 'fs' for readFile support */
import * as fs from 'fs';
set_fs(fs);
/* Parse `pres.xlsx`` */
const wb = readFile("pres.xlsx");
/* Create a folder `csv` */
try { fs.mkdirSync("csv"); } catch(e) {}
/* Generate CSV data for each worksheet */
wb.SheetNames.forEach((name, idx) => {
const ws = wb.Sheets[name];
const csv = utils.sheet_to_csv(ws);
fs.writeFileSync(`csv/${idx}.csv`, csv);
});
/* Create documents with DirectoryLoader */
const loader = new DirectoryLoader("csv", {
".csv": (path) => new CSVLoader(path)
});
const docs = await loader.load();
console.log(docs);
// ...
SheetJS Loader
The LangChainJS CSVLoader does not add any Document metadata and does not
generate any attributes. A custom loader can work around limitations in the CSV
tooling and potentially include metadata that has no CSV equivalent.
The demo LoadOfSheet loader will
generate one Document per data row across all worksheets. It will also attempt
to build metadata and attributes for use in self-querying retrievers.
/* read and parse `data.xlsb` */
const loader = new LoadOfSheet("./data.xlsb");
/* generate documents */
const docs = await loader.load();
/* synthesized attributes for the SelfQueryRetriever */
const attributes = loader.attributes;
Sample SheetJS Loader (click to show)
This example loader pulls data from each worksheet. It assumes each worksheet includes one header row and a number of data rows.
import { Document } from "@langchain/core/documents";
import { BufferLoader } from "langchain/document_loaders/fs/buffer";
import { read, utils } from "xlsx";
/**
* Document loader that uses SheetJS to load documents.
*
* Each worksheet is parsed into an array of row objects using the SheetJS
* `sheet_to_json` method and projected to a `Document`. Metadata includes
* original sheet name, row data, and row index
*/
export default class LoadOfSheet extends BufferLoader {
/** @type {import("langchain/chains/query_constructor").AttributeInfo[]} */
attributes = [];
/**
* Document loader that uses SheetJS to load documents.
*
* @param {string|Blob} filePathOrBlob Source Data
*/
constructor(filePathOrBlob) {
super(filePathOrBlob);
this.attributes = [];
}
/**
* Parse document
*
* NOTE: column labels in multiple sheets are not disambiguated!
*
* @param {Buffer} raw Raw data Buffer
* @param {Document["metadata"]} metadata Document metadata
* @returns {Promise<Document[]>} Array of Documents
*/
async parse(raw, metadata) {
/** @type {Document[]} */
const result = [];
this.attributes = [
{ name: "worksheet", description: "Sheet or Worksheet Name", type: "string" },
{ name: "rowNum", description: "Row index", type: "number" }
];
const wb = read(raw, {type: "buffer", WTF:1});
for(let name of wb.SheetNames) {
const fields = {};
const ws = wb.Sheets[name];
if(!ws) return;
const aoo = utils.sheet_to_json(ws);
aoo.forEach((row, idx) => {
result.push({
pageContent: "Row " + (idx + 1) + " has the following content: \n" + Object.entries(row).map(kv => `- ${kv[0]}: ${kv[1]}`).join("\n") + "\n",
metadata: {
worksheet: name,
rowNum: row["__rowNum__"],
...metadata,
...row
}
});
Object.entries(row).forEach(([k,v]) => { if(v != null) (fields[k] || (fields[k] = {}))[v instanceof Date ? "date" : typeof v] = true } );
});
Object.entries(fields).forEach(([k,v]) => this.attributes.push({
name: k, description: k, type: Object.keys(v).join(" or ")
}));
}
return result;
}
};
From Text to Binary
Many libraries and platforms offer generic "text" loaders that process files assuming the UTF-8 encoding. This corrupts many spreadsheet formats including XLSX, XLSB, XLSM and XLS.
This issue affects many JavaScript tools. Various demos cover workarounds:
-
ViteJS plugins receive the relative path to the workbook file and can read the file directly.
-
Webpack plugins support a special
rawoption that instructs the bundler to pass raw binary data. -
NuxtJS parsers and transformers can deduce the path to the workbook file from internal identifiers.
The CSVLoader extends a special TextLoader that forces UTF-8 text parsing.
There is a separate BufferLoader class, used by the PDF loader, that passes
the raw data using NodeJS Buffer objects.
| Binary | Text |
|---|---|
pdf.ts (structure) | csv.ts (structure) |
NodeJS Buffers
The SheetJS read method supports NodeJS Buffer objects directly7:
import { BufferLoader } from "langchain/document_loaders/fs/buffer";
import { read, utils } from "xlsx";
export default class LoadOfSheet extends BufferLoader {
// ...
async parse(raw, metadata) {
const wb = read(raw, {type: "buffer"});
// At this point, `wb` is a SheetJS workbook object
// ...
}
}
The read method returns a SheetJS workbook object4.
Generating Content
The SheetJS sheet_to_json method8 returns an array of data objects whose
keys are drawn from the first row of the worksheet.
| Spreadsheet | Array of Objects |
|---|---|
| |
The original CSVLoader wrote one row for each key-value pair. This text can be
generated by looping over the keys and values of the data row object. The
Object.entries helper function simplifies the conversion:
function make_csvloader_doc_from_row_object(row) {
return Object.entries(row).map(([k,v]) => `${k}: ${v}`).join("\n");
}
Generating Documents
The loader must generate row objects for each worksheet in the workbook.
In the SheetJS data model, the workbook object has two relevant fields:
SheetNamesis an array of sheet namesSheetsis an object whose keys are sheet names and values are sheet objects.
A for..of loop can iterate across the worksheets:
const wb = read(raw, {type: "buffer", WTF:1});
for(let name of wb.SheetNames) {
const ws = wb.Sheets[name];
const aoa = utils.sheet_to_json(ws);
// at this point, `aoa` is an array of objects
}
This simplified parse function uses the snippet from the previous section:
async parse(raw, metadata) {
/* array to hold generated documents */
const result = [];
/* read workbook */
const wb = read(raw, {type: "buffer", WTF:1});
/* loop over worksheets */
for(let name of wb.SheetNames) {
const ws = wb.Sheets[name];
const aoa = utils.sheet_to_json(ws);
/* loop over data rows */
aoa.forEach((row, idx) => {
/* generate a new document and add to the result array */
result.push({
pageContent: Object.entries(row).map(([k,v]) => `${k}: ${v}`).join("\n")
});
});
}
return result;
}
Metadata and Attributes
It is strongly recommended to generate additional metadata and attributes for self-query retrieval applications.
Implementation Details (click to show)
Metadata
Metadata is attached to each document object. The following example appends the raw row data to the document metadata:
/* generate a new document and add to the result array */
result.push({
pageContent: Object.entries(row).map(([k,v]) => `${k}: ${v}`).join("\n"),
metadata: {
worksheet: name, // name of the worksheet
rowNum: idx, // data row index
...row // raw row data
}
});
Attributes
Each attribute object specifies three properties:
namecorresponds to the field in the document metadatadescriptionis a description of the fieldtypeis a description of the data type.
While looping through data rows, a simple type check can keep track of the data type for each column:
for(let name of wb.SheetNames) {
/* track column types */
const fields = {};
// ...
aoo.forEach((row, idx) => {
result.push({/* ... */});
/* Check each property */
Object.entries(row).forEach(([k,v]) => {
/* Update fields entry to reflect the new data point */
if(v != null) (fields[k] || (fields[k] = {}))[v instanceof Date ? "date" : typeof v] = true
});
});
// ...
}
Attributes can be generated after writing the worksheet data. Storing attributes in a loader property will make it accessible to scripts that use the loader.
export default class LoadOfSheet extends BufferLoader {
attributes = [];
// ...
async parse(raw, metadata) {
// Add the worksheet name and row index attributes
this.attributes = [
{ name: "worksheet", description: "Sheet or Worksheet Name", type: "string" },
{ name: "rowNum", description: "Row index", type: "number" }
];
const wb = read(raw, {type: "buffer", WTF:1});
for(let name of wb.SheetNames) {
const fields = {};
// ...
const aoo = utils.sheet_to_json(ws);
aoo.forEach((row, idx) => {
result.push({/* ... */});
/* Check each property */
Object.entries(row).forEach(([k,v]) => {
/* Update fields entry to reflect the new data point */
if(v != null) (fields[k] || (fields[k] = {}))[v instanceof Date ? "date" : typeof v] = true
});
});
/* Add one attribute per metadata field */
Object.entries(fields).forEach(([k,v]) => this.attributes.push({
name: k, description: k,
/* { number: true, string: true } -> "number or string" */
type: Object.keys(v).join(" or ")
}));
}
// ...
}
SheetJS Loader Demo
The demo performs the query "Which rows have over 40 miles per gallon?" against a sample cars dataset and displays the results.
This demo was tested using the Phi-49 in Ollama.
The tested model used up to 10GB VRAM. It is strongly recommended to run the demo on a GPU with at least 12GB VRAM or a newer Apple Silicon Mac with at least 32GB unified memory.
- Install pre-requisites:
Ollama should be installed on the same platform as NodeJS. If NodeJS is run within WSL, Ollama should also be installed within WSL.
Intel ARC GPUs require the Intel Extension for PyTorch (IPEX) and a special version of Ollama that ships with the associated LLM Library (IPEX-LLM).
ARC Instructions on Windows (click to show)
These instructions are based on the official Intel recommendations.
A) If Ollama for Windows was installed, close the program by right-clicking on the tray icon and selecting "Quit Ollama".
B) Install Miniforge310, selecting "Just Me" when prompted.
C) Launch a normal Command Prompt and create a Conda environment:
cd %USERPROFILE%\Documents
mkdir ollama-intel
cd ollama-intel
set PATH=%PATH%;%USERPROFILE%\miniforge3\condabin
conda create -n llm-cpp python=3.11
D) Activate the environment in the session and install dependencies:
conda activate llm-cpp
pip install --pre --upgrade ipex-llm[cpp]
Close the window after the installation.
E) Launch a new Administrator Command Prompt and set up Ollama:
cd %USERPROFILE%\Documents\ollama-intel
set PATH=%PATH%;%USERPROFILE%\miniforge3\condabin
conda activate llm-cpp
init-ollama.bat
Close the window.
F) Launch a normal Command Prompt window and run Ollama:
cd %USERPROFILE%\Documents\ollama-intel
set PATH=%PATH%;%USERPROFILE%\miniforge3\condabin
conda activate llm-cpp
set OLLAMA_NUM_GPU=999
set no_proxy=localhost,127.0.0.1
set ZES_ENABLE_SYSMAN=1
set SYCL_CACHE_PERSISTENT=1
set SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
ollama serve
This window should be kept open throughout the demo.
ARC Instructions on Linux (click to show)
These instructions are based on the official Intel recommendations.
A) Install the dependencies from the Battlemage quickstart
B) Download and extract the Ollama Portable Zip.
C) When this demo was last tested, the computer had an AMD processor. To force
Ollama to use the GPU, uncomment the "single GPU" line in start-ollama.sh:
export ONEAPI_DEVICE_SELECTOR=level_zero:0
D) Run the start-ollama.sh script from the extracted folder.
After installing dependencies, start a new terminal session.
- Create a new project:
mkdir sheetjs-loader
cd sheetjs-loader
npm init -y
- Download the demo scripts:
curl -LO https://docs.sheetjs.com/loadofsheet/query.mjs
curl -LO https://docs.sheetjs.com/loadofsheet/loadofsheet.mjs
In PowerShell, the command may fail with a parameter error:
Invoke-WebRequest : A parameter cannot be found that matches parameter name 'LO'.
curl.exe must be invoked directly:
curl.exe -LO https://docs.sheetjs.com/loadofsheet/query.mjs
curl.exe -LO https://docs.sheetjs.com/loadofsheet/loadofsheet.mjs
- Install the SheetJS NodeJS module:
npm i --save https://sheet.lol/balls/xlsx-0.20.3.tgz
- Install dependencies:
npm i --save @langchain/[email protected] [email protected] @langchain/[email protected] [email protected]
In some test runs, there were error messages relating to dependency and peer
dependency versions. The --force flag will suppress version mismatch errors:
npm i --save @langchain/[email protected] [email protected] @langchain/[email protected] [email protected] --force
- Download the cars dataset:
curl -LO https://docs.sheetjs.com/cd.xls
In PowerShell, the command may fail with a parameter error:
Invoke-WebRequest : A parameter cannot be found that matches parameter name 'LO'.
curl.exe must be invoked directly:
curl.exe -LO https://docs.sheetjs.com/cd.xls
- Install the
phi4:14bmodel using Ollama:
ollama pull phi4:14b
Additional steps for Intel GPUs (click to show)
A different embedding model must be used on Intel GPUs:
A) Install the nomic-embed-text:latest model through Ollama:
ollama pull nomic-embed-text:latest
B) Edit query.mjs to use the embedding model:
const llm = new ChatOllama({ baseUrl: "http://127.0.0.1:11434", model });
const embeddings = new OllamaEmbeddings({ baseUrl: "http://127.0.0.1:11434", model: "nomic-embed-text:latest"});
- Run the demo script
node query.mjs
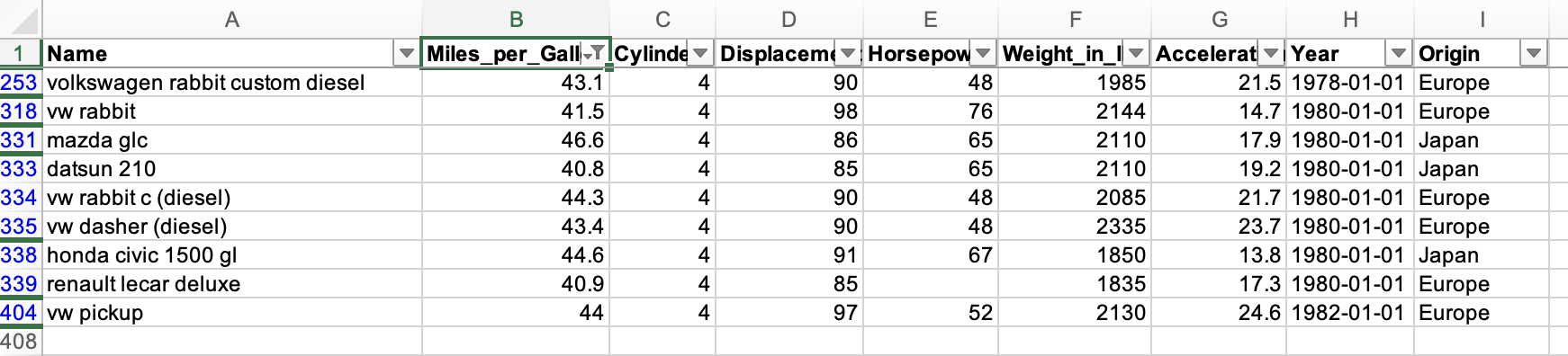
The demo performs the query "Which rows have over 40 miles per gallon?". It will print the following nine results:
{ Name: 'volkswagen rabbit custom diesel', MPG: 43.1 }
{ Name: 'vw rabbit c (diesel)', MPG: 44.3 }
{ Name: 'renault lecar deluxe', MPG: 40.9 }
{ Name: 'honda civic 1500 gl', MPG: 44.6 }
{ Name: 'datsun 210', MPG: 40.8 }
{ Name: 'vw pickup', MPG: 44 }
{ Name: 'mazda glc', MPG: 46.6 }
{ Name: 'vw dasher (diesel)', MPG: 43.4 }
{ Name: 'vw rabbit', MPG: 41.5 }
Some SheetJS users with older GPUs have reported errors.
If the command fails, please try running the script a second time.
To find the expected results:
- Open the
cd.xlsspreadsheet in Excel - Select Home > Sort & Filter > Filter in the Ribbon
- Select the filter option for column B (
Miles_per_Gallon) - In the popup, select "Greater Than" in the Filter dropdown and type 40
The filtered results should match the following screenshot:
The SheetJS model exposes formulae and other features.
SheetJS Pro builds expose cell styling, images, charts, tables, and other features.
Footnotes
-
See "How to load CSV data" in the LangChain documentation ↩
-
See "Workbook Object" ↩ ↩2
-
See "Folders with multiple files" in the LangChain documentation ↩
-
See the Phi-4 Technical Report for more details. ↩
-
Select "Windows"
x86_64in the Installation page. ↩